Die Mainzelliste - Pseudonymisierung und Identitätsmanagement
Die Mainzelliste ist ein webbasierter Pseudonymisierungsdienst erster Stufe. Sie erlaubt die Erzeugung von Personenidentifikatoren (PID) aus identifizierenden Attributen (IDAT), dank Record-Linkage-Funktionalität auch bei schlechter Qualität identifizierender Daten. Ihre Funktionen werden über eine REST-Schnittstelle bereitgestellt.
Ein Anwendungszweck sind multizentrische Forschungsvorhaben: Dazu wird die Mainzelliste von einer vertrauenswürdigen dritten Stelle betrieben, um einheitliche, aber nicht identifizierende Personenidentifikatoren zu erzeugen, ggfls. auch mehrere pro angebundenem System. So sind einerseits Daten jedes Probanden über Institutionsgrenzen hinaus verknüpfbar, andererseits kann zur Wahrung datenschutzrechtlicher Vorgaben eine informationelle Gewaltenteilung samt pseudonymisierter Speicherung umgesetzt werden.
Die Mainzelliste wird entwickelt, um als Nachfolger des sog. „PID-Generators“ (Prof. Dr. Klaus Pommerening, Universitätsmedizin Mainz) die Anforderungen an die Patientenliste des revidierten Datenschutzkonzepts der TMF zu erfüllen.
Ein Anwendungszweck sind multizentrische Forschungsvorhaben: Dazu wird die Mainzelliste von einer vertrauenswürdigen dritten Stelle betrieben, um einheitliche, aber nicht identifizierende Personenidentifikatoren zu erzeugen, ggfls. auch mehrere pro angebundenem System. So sind einerseits Daten jedes Probanden über Institutionsgrenzen hinaus verknüpfbar, andererseits kann zur Wahrung datenschutzrechtlicher Vorgaben eine informationelle Gewaltenteilung samt pseudonymisierter Speicherung umgesetzt werden.
Die Mainzelliste wird entwickelt, um als Nachfolger des sog. „PID-Generators“ (Prof. Dr. Klaus Pommerening, Universitätsmedizin Mainz) die Anforderungen an die Patientenliste des revidierten Datenschutzkonzepts der TMF zu erfüllen.
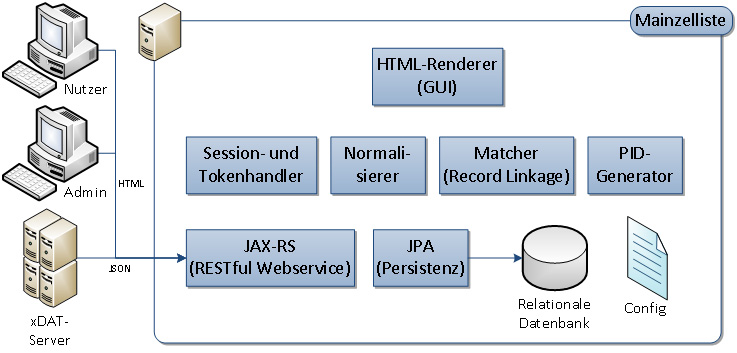
Funktionalität
Erstellung nichtsprechender Pseudonyme (PID-Generierung)
Die Mainzelliste erzeugt für jeden eingetragenen Patienten einen oder mehrere nichtsprechende sogenannte Personenidentifikatoren (PID), die kompatibel zu denen des ursprünglichen PID-Generators sind. Diese deterministisch erzeugten achtstelligen Zeichenketten eignen sich sowohl für den Webeinsatz als auch manuelle Übertragung, da sie bis zu zwei Tippfehler erkennen können [1].Record Linkage
Für jeden Patienten soll auch bei mehrmaliger Eingabe nur genau ein Pseudonym erzeugt werden. Dazu wird bei Anlage eines Patienten geprüft, ob dieser schon in der Datenbank vorhanden ist. Dank eines modularen Record-Linkage-Systems, das mit Hilfe einer Konfigurationsdatei flexibel an die Anforderungen des konkreten Anwendungsfalls angepasst werden kann, gelingt dies auch bei abweichender Schreibweise oder Vertippen. Neu im Vergleich zum PID-Generator ist insbesondere die Möglichkeit, eigene phonetische Codes sowie Zeichenkettenvergleiche zu nutzen, wodurch auch Namen aus anderen Sprachräumen fehlertolerant verglichen werden können. Derzeit wird ein gewichtsbasiertes Record Linkage unterstützt, die modulare Konzeption erlaubt aber auch die Nachrüstung eigener Algorithmen. Die Möglichkeit, unsicherere Zuordnungen manuell nachzubearbeiten, unterstützt darüber hinaus das automatische Matchverfahren.REST-basierte Webschnittstelle
Eine leichtgewichtige REST-basierte [2] Schnittstelle erlaubt eine einfache Anbindung unterschiedlichster Systeme, also z.B. Registern, Biobanken, EDC- und Studienmanagementsystemen. Das macht überhaupt erst die Verwendung aus Webbrowsern über AJAX- und JSONP-Aufrufe möglich. Implementierungen existieren u.a. für das Studienmanagementsystem SecuTrial der Firma iAS.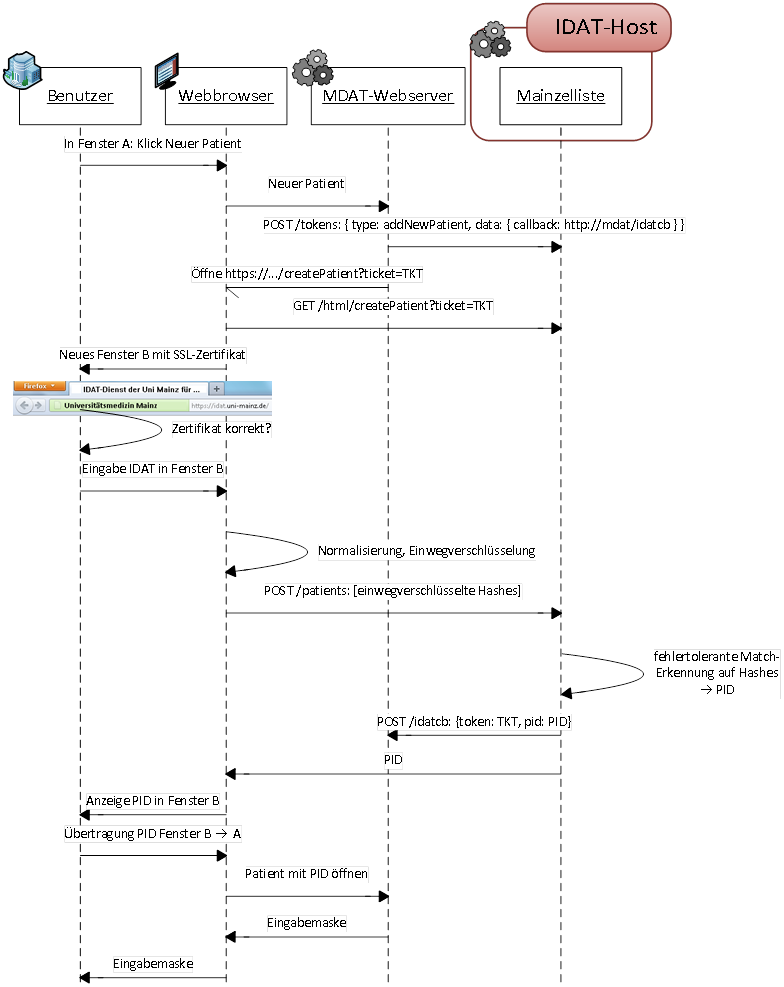
Nutzer- und Administrationsschnittstelle
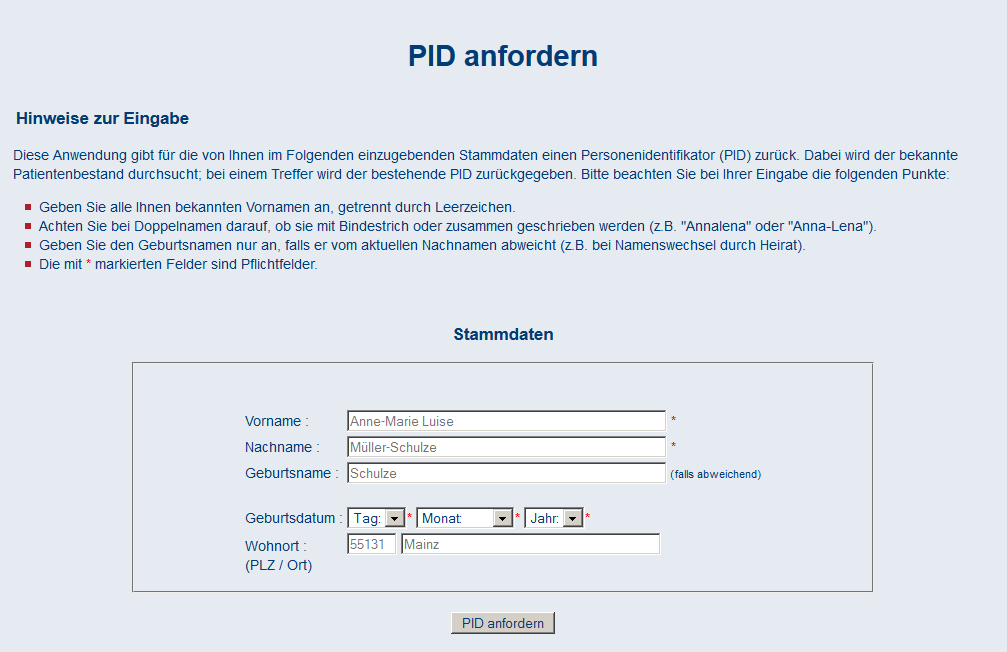
Die Komplexität des Record Linkage bleibt dem Nutzer verborgen, da er identifizierende Patientendaten über eine leicht verständliche, schlanke Bedienoberfläche in seinem Webbrowser eingibt.Etwaige Fehler des Record Linkage können in einer administrativen Bedienoberfläche korrigiert werden (Implementierung ist in Arbeit). Entsprechende Meldefunktionen vereinfachen den Prozess für Nutzer und Administratoren.
Abwärtskompatibilität
Für Verbünde, die noch den PID-Generator einsetzen, steht in den allermeisten Fällen ein Migrationspfad auf die Mainzelliste zur Verfügung. Dafür wurde die Phonetik nach dem Phonet-Algorithmus von Jörg Michael [3] im Rahmen einer Evaluation in Java reimplementiert [4].Zusammenführung verschiedener Datenklassen in Webbrowsern
In manchen behandlungsnahen Anwendungen ist es zulässig und wünschenswert, dass Nutzer anstelle von Pseudonymen Klarnamen sehen. Die REST-Schnittstelle der Mainzelliste ermöglicht prinzipiell deren Abruf, aber einige moderne und fast alle betagten Webbrowser halten für eine stabile Implementierung diverse Hürden bereit, u.a. die Same-Origin-Policy [5]. Die Mainzelliste hilft diese Hindernisse zu umschiffen, indem sie Zugriffe durch die Mainzer Datenschutzbibliothek erlaubt (Implementierung erfolgt im Rahmen des Projekts OSSE).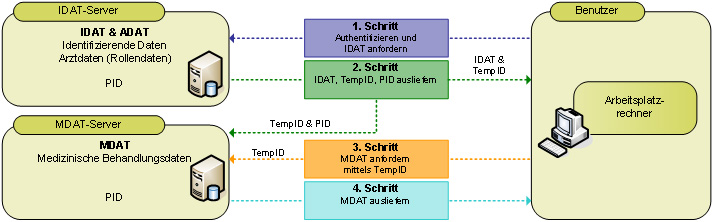
Temporäre Identifikatoren
In manchen behandlungsnahen Anwendungen sind permanente Pseudonyme vor dem Nutzer zu verbergen. An ihre Stelle treten temporär gültige Pseudonyme (TempIDs), die durch die Mainzer Datenschutzbibliothek (Implementierung erfolgt im Rahmen des Projekts OSSE) erzeugt, zwischen den beteiligten Servern ausgetauscht und aufgelöst werden können.Verbreitung
Die Mainzelliste wird bereits in einer Vielzahl von Projekten eingesetzt und ihre Schnittstelle wurde in verschiedenen Softwareprodukten für die medizinische Forschungs implementiert. Die aktuelle Liste von Nutzungsreferenzen finden Sie auf der Projektseite auf Bitbucket.Download
Alles, was Sie für eine eigene Mainzelliste benötigen, können Sie hier direkt downloaden (sie werden auf eine Übersicht der verfügbaren Versionen weitergeleitet). Bitte beachten Sie die Nutzungsbedingungen weiter unten auf dieser Seite.
Zitation
Wenn Sie in Literatur auf die Mainzelliste verweisen wollen, zitieren Sie bitte den folgenden Artikel zu Konzept und Schnittstelle des Programms:Lablans M, Borg A, Ückert F: A RESTful interface to pseudonymization services in modern web applications. BMC Med Inform Decis Mak. 2015 Feb 7;15:2. doi: 10.1186/s12911-014-0123-5.
Mailingliste und Kontakt
Um immer auf dem aktuellen Stand zu bleiben, registrieren Sie sich auf unserer Mailingliste.Die Entwickler können Sie unter der Adresse info@mainzelliste.de erreichen.
Mitmachen im BitBucket!
Wir haben uns entschieden, den Code der Mainzelliste im Repository-Dienst „BitBucket“ für die gemeinsame Bearbeitung verfügbar zu machen. Dieser Dienst der Firma Atlassian unterstützt die verteilten Versionskontrollsysteme Git und Mercurial und ist in der Basisversion kostenlos erhältlich. Bitbucket stellt alle nötigen Features für das Repository-Management zur Verfügung (Code-Browser, Forks, Commit-History etc.) und bietet mit einem integrierten Wiki sowie einem Issue-Tracking-System auch zusätzliche Werkzeuge an.Sie finden unser Repository hier.
Dokumentation
Es ist relativ einfach, die Entwicklungsumgebung für die Mainzelliste aufzusetzen und das Programm lokal in Betrieb zu nehmen. Zusammen mit ein paar weiteren Informationen können Sie dies in unserer Anleitung für Entwickler nachlesen.- Anleitung für Entwickler(PDF 98,4 KB): Beschreibt die Einrichtung einer Entwicklungsumgebung zur Weiterentwicklung des Programmcodes.
- Konfigurationshandbuch(PDF 418,6 KB): Beschreibt die Parameter, die in der Konfigurationsdatei der Mainzelliste verwendet werden, etwa zur Parametrierung des Record Linkage.
- Installationsanleitung(PDF 101,1 KB): Beschreibt die Installation einer Instanz der Mainzelliste auf einem Webserver.
- Anleitung für den MDAT-Admin(PDF 180,4 KB): Beschreibt, wie die Schnittstelle der Mainzelliste von anderen Webanwendungen (z.B. einer Registersoftware) benutzt werden kann, um die Pseudonymisierung transparent einbinden zu können.
- Schnittstelle der Mainzelliste(PDF 440,3 KB): Eine formale Spezifikation der Schnittstelle als umfassender Überblick über die Funktionalität sowie als Referenz für Entwickler, welche die Schnittstelle client- oder serverseitig implementieren.
Konfigurationsdatei
Die Einträge in der Konfiguration sind von entscheidender Bedeutung für korrekte Matchinggewichte und -schranken. Diese haben Ihnen wir aufgrund der umfangreichen Erfahrungen an unserem Institut bereits lauffähig angegeben.Nutzungsbedingungen
Die Mainzelliste – Ein Werkzeug zur Pseudonymisierung
Copyright © 2013 Martin Lablans, Andreas Borg, Frank Ückert
Dieses Programm ist freie Software: Sie können Sie unter den Bedingungen der GNU Affero General Public License (AGPL), entweder der Version 3 der Lizenz oder einer späteren Version, veröffentlicht von der Free Software Foundation, weiterverbreiten und/oder modifizieren. Sie sollten eine Kopie der AGPL mit der Software erhalten haben. Wenn nicht, sehen Sie unter http://www.gnu.org/licenses/ nach. Wenn Ihre Software mit entfernten Benutzern über ein Computernetzwerk interagiert, müssen Sie sicherstellen, dass es einen Weg für Ihre Benutzer gibt, den Source Code (Quelltext) der (auch von Ihnen geänderten) Software herunterzuladen. Zum Beispiel könnte Ihre Website (bei einer Webapplikation) einen Link zu einem Archiv mit dem Quelltext bereitstellen (siehe auch Artikel 13 der AGPL).
Die folgende Kurzfassung ersetzt nicht den Lizenztext. In Kürze bedeutet die GNU Affero General Public License:
- Sie dürfen die Software kostenlos herunterladen und nicht-kommerziell wie auch kommerziell verwenden.
- Sie müssen die Lizenz (GNU Affero General Public License) beibehalten, wenn Sie die Software oder Teile der Software weiterverbreiten. Sie dürfen die Software oder Teile davon NICHT unter irgendeiner anderen Lizenz verbreiten.
- Eine Weiterverbreitung liegt auch vor, wenn Sie die Software als Dienst über ein Netzwerk zur Verfügung stellen.
Eine Mainzelliste ohne jeden Aufwand
Sie haben Interesse an der Nutzung einer Mainzelliste zur Pseudonymisierung, beispielsweise für Ihren Forschungsverbund in der Medizin? Sie wollen aber die Software nicht in eigener Arbeit verstehen und in Betrieb nehmen? Sie haben keine passende Hardware verfügbar oder wollen bzw. können nicht selbst als Betreiber einer Mainzelliste auftreten? Dann haben wir eine Lösung für Sie:

Die Mainzelliste kann im Rahmen von wissenschaftlichen Kooperationen von uns betrieben werden. Wenn Sie einen Betrieb mit Verfügbarkeitsgarantien und entsprechenden Haftungen wünschen, können wir Ihnen zumindest einen zuverlässigen, externen Partner aus der Wirtschaft empfehlen. Umfangreiche Beispielverträge sind vorhanden und können direkt genutzt werden.
Quellen
- Faldum A., Pommerening K., An optimal code for patient identifiers. Computer methods and programs in biomedicine, 2005. 79: p. 81-8.
- Fielding R.T., Architectural Styles and the Design of Network-based Software Architectures, in Building, R.N. Taylor, Editor. 2000, Citeseer. p. 162.
- Michael J., Doppelgänger gesucht – Ein Programm für kontextsensitive phonetische Textumwandlung. c’t Magazin für Computertechnik, 1999. 25.
- Warnecke T., Borg A., Ückert F., Lablans M., Fehlertolerantes Record Linkage von Patientendaten durch den Phonet-Algorithmus, http://www.egms.de/static/en/meetings/gmds2013/13gmds055.shtml.
- Lablans, M., et al. Eine generische Softwarebibliothek zur Umsetzung des TMF-Datenschutzkonzepts A im Webeinsatz. in 55. Jahrestagung der Deutschen Gesellschaft für Medizinische Informatik, Biometrie und Epidemiologie (gmds). 2010.
- Lablans M, Borg A, Ückert F: A RESTful interface to pseudonymization services in modern web applications. BMC Med Inform Decis Mak. 2015 Feb 7;15:2. doi: 10.1186/s12911-014-0123-5.